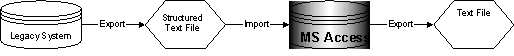
Sample Work
Manufacturing Resources Planning, SAP Migration- MS Access Database
Previously unpublished work by M. A. Meshkot M.Sc., Ph.D., D.I.C.,
Dated April 1999
Copyright ® 1999 M. A. Meshkot, Web published November 2003
SAP R/3 is the world's most-used standard business software for client/server computing (SAP). This article concerns the migration of databases from legacy mainframe systems to SAP R/3 through an Access database. The MS Access database was used to enable data checking and manipulation during the transfer process. Data that required verification or change, was presented on user forms. Users, depending on their security level, could change the presented data fields. Any changes were recorded in one of two audit trails. One trail recorded the difference between any fields of any record of successively imported text files, whilst the other audit trail showed exactly who changed what and when in the Access user interface. Below is a description of the overall functionality of the Access database and the naming convention used, which tells a lot about the structure of the database.
Text files were exported from the legacy system by Cobol programming. These files often contained many tables from a relational database.
Figure 1 below, describes the structure of a typical text file. Each text file contained a header record HDR and an END record at the end. Between these two records, lines of text represented records of different type, length and structure. A text file definition table described the structure of each text file. The definition table was like a sub-database which described the data structure of the main database. The definition table was needed because each text file contained a separate database, also called business objects.
Figure 1¢ Structure of Legacy Download Files
HDRnnnllssaappddddddddtttttt
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
4ssssssssAAAAAttttttttttuuuuuuuuuuuuuuuuuuuuuvvvvvvvvvvvvvvv
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
4ssssssssAAAAAttttttttttuuuuuuuuuuuuuuuuuuuuuvvvvvvvvvvvvvvv
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
4ssssssssAAAAAttttttttttuuuuuuuuuuuuuuuuuuuuuvvvvvvvvvvvvvvv
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
4ssssssssAAAAAttttttttttuuuuuuuuuuuuuuuuuuuuuvvvvvvvvvvvvvvv
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
4ssssssssAAAAAttttttttttuuuuuuuuuuuuuuuuuuuuuvvvvvvvvvvvvvvv
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
1aaaaaaaaaabbbbbcccccccKKKKKddddddddddddeeeeeeeeeeffghhhhhhhhhiiii
2jjkllllllllmmmmKKKKKooooooooAAAAAppppppppp
3KKKKKqqqqqqqqqqqqqqqqrrrrrrrrr
END
Four record types are shown in the example of Figure 1 as indicated by the first character of each line; except for the header record (HDR) and the END record.
Each record contains a number of fields which contain data from the legacy system. The key fields are indicated by capital letters.
The first and main job of the Access database was to read the import file for each business object and reorganise its data into a tabular format. Such that there is one table for each record type (1, 2, 3ģ) and one column for each field (aaaaaaaaaa,bbbbb,cccccccģ)of that record type in the table. An example is shown below:
Table 1 ¢ Type 1 Records. Extraction and organisation of type 1 records from the import file into a separate table
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
| 1 | aaaaaaaaa | bbbbb | ccccccc | KKKKK | dddddddddddd | eeeeeeeeee | ff | g | hhhhhhhhh | iiii |
Table 2¢ Type 2 Records. Extraction and organisation of type 2 records from the import file into a separate table
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
| 2 | jj | k | llllllll | mmmm | KKKKK | oooooooo | AAAAA | ppppppppp |
Table 3 ¢ Type 3 Records. Extraction and organisation of type 3 records from the import file into a separate table
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
| 3 | KKKKK | qqqqqqqqqqqqqqqq | rrrrrrrrr |
Table 4 ¢ Type 4 Records. Extraction and organisation of type 4 records from the import file into a separate table
| 4 | ssssssss | AAAAA | tttttttttt | uuuuuuuuuuuuuuuuuuuuu | vvvvvvvvvvvvvvv |
| 4 | ssssssss | AAAAA | tttttttttt | uuuuuuuuuuuuuuuuuuuuu | vvvvvvvvvvvvvvv |
| 4 | ssssssss | AAAAA | tttttttttt | uuuuuuuuuuuuuuuuuuuuu | vvvvvvvvvvvvvvv |
| 4 | ssssssss | AAAAA | tttttttttt | uuuuuuuuuuuuuuuuuuuuu | vvvvvvvvvvvvvvv |
| 4 | ssssssss | AAAAA | tttttttttt | uuuuuuuuuuuuuuuuuuuuu | vvvvvvvvvvvvvvv |
Since data was continually being changed and updated, the process of exporting text files from the legacy system and importing them into Access was a batch process which was repeated daily. Therefore the process of creating data tables in Access from text files legacy downloads had to be an automated process. Further, the Access program needed to detect and highlight the data that had been changed in the legacy system after each legacy download was imported.
In the naming convention, Current data refers to freshly imported data from the legacy system and Previous data refers to data that has been superseded.
The following naming convention was devised for Objects within the Access database.
The table name convention was designed to be flexible. Therefore table names were not site-specific, activity-specific, business-object specific or content-type specific. In other words, all this information was encompassed in the table name.
Table names were fixed length and complied with the following naming convention:
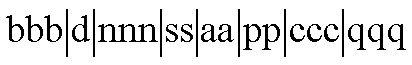
Table 5 - Description of the table name components
| Table-Name Component | Component Name | Meaning |
| bbb | Object Indicator | Literal ōtblö stands for Table. |
| d | Data Direction indicator | Literal ōIö meaning Import or ōEö for Export. |
| nnn | Business Object ID number | e.g. 099, 135, 4AA, 400 |
| ss | Site identifier | Set to LN for London. |
| aa | Activity Group | set to PS for Product Sales and PR for Product Research. |
| pp | Stage indicator | Set to 01 for Stage 1. |
| ccc | Contents indicator | Set to Txt for text imported as one line of text per record. Set to Sxx for tables containing data from a Segment, where xx is the segment indicator. e.g. S01, S02, S03, S0A, S0B. |
| qqq | Sequence indicator | Set to ōCurö for Current data Set to ōPrvö for Previously imported data. |
For example, table name tblI099LNPS01S02Cur refers to the Stage 1 data table holding imported current data for segment 2 of Business Object 099 for Product Sales in London.
The following database tables were created in Access as control tables containing information about the database. Such tables were not subject to the Business Object Table name conventions. All control data tables resided in the controller backend part of the 2-part Access database.
Table 6 ¢ List and description of control tables
| Table Name | Description |
| tblBOIRD | Business Object Import Record Definition table. This table defined the file structure for text files to be imported. |
| tblBOERD | Business Object Export Record Definition table. This table defined the file structure for text files to be exported. |
| tblBOIRDReview | Table containing a record of BOIRD checking and verification |
| tblBusinessObjects | List of business objects, which were database to pass through Access. |
| tblBusObjForms | List of forms created for each business object |
| tblBusObjUsers | List of users with access permissions for each business object. |
| tblErrLog | Error log |
| tblFormList | List of forms which span more than one business object |
| tblFormUsers | List of users with permissions for each form |
| tblHRDEND | Header and End records for all imported text files containing file details and date/time stamps. |
| tblValidUserList | List of valid users and user groups, from which form and business object users were selected. |
All query names began with the literal qry and complied with the following naming convention:
Query names for controls, such as sub-forms, sub-reports, list and combo boxes were freeform descriptive, and related to the control name.
The query name convention was designed to be flexible. Therefore query names were not site-specific, activity-specific, business-object specific or content-type specific. In other words, all this information was encompassed in the query name.
The name for queries linked to user data entry forms complied with the following convention.
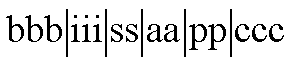
Table 7 - Description of the query name components
| Query-Name Component | Component Name | Meaning |
| bbb | Object Indicator | Literal ōqryö stands for Query. |
| iii | ID Number | Set to nnn = the Business Object ID number when the query is confined to one business object. E.g.
099, 554, 80A, 400. Set to Mnn when the query spans business objects, where nn is a sequential query number, e.g. M01, M02, M03. |
| ss | Site identifier | Set to LN for London. |
| aa | Activity Group | Set to PS for Product Sales and PR for Product Research. |
| pp | Stage indicator | Set to 01 for Stage 1. |
| ccc | Contents indicator | Set to Sxx for queries containing data from one segment, where xx is the segment
indicator, e.g. S01, S02, S03, S0A, S0B. Set to Myy for queries containing data from multiple segments where yy is a sequential integer starting at 01. e.g. M01, M02, M03 |
For example, query name qry99BLNPS01S02 identifies a Stage 1 query, which refers to fields in segment 2 of Business Object 99B for Product Sales in London.
Queries designed to highlight the differences between the current and previous segment data tables, that is the difference between two successive legacy system downloads, complied with table 7 above, and in addition had the literal drp appended to the query name.
Forms designed for data entry by users complied with the naming convention for Data Entry Form Names below
Forms designed for the back-end control database for data entry by the controller were descriptive, based on the underlying table or query name where one was defined, and were freeform with variable length.
All form names were preceded by the literal frm. Sub-form names were preceded by the literal frs.
A number of non data-entry forms were also created. These included dynamically created forms to display error codes and to communicate with users when user errors were trapped. These forms had specific names, such as frmUserMessage and the form control properties, such as text and colour were altered by program code. Other non data-entry forms included those in which business objects and their associated forms were displayed for users to choose from.
The form name convention was designed to be flexible. Therefore form names were not site-specific, activity-specific, business-object specific or content-type specific. In other words, all this information was encompassed in the form name.
Form names were fixed length and complied with the following naming convention:
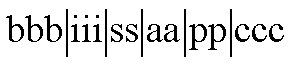
Table 9 ¢ Description of the components of data entry form names
| Form-Name Component | Component Name | Meaning |
| bbb | Object Indicator | Literal ōfrmö stands for Form. |
| iii | ID Number | Set to nnn = the Business Object ID number when the form is confined to one business object. E.g.
099, 450, 09A, 400. Set to Mnn when the form spans business objects, where nn is the underlying sequential query number, e.g. M01, M02, M03. |
| ss | Site identifier | Set to LN for London. |
| aa | Activity Group | Set to PS for Product Sales and PR for Product Research. |
| pp | Stage indicator | Set to 01 for Stage 1. |
| ccc | Contents indicator | Set to Sxx for forms containing data from one segment, where xx is the segment
indicator, e.g. S01, S02, S03, S0A, S0B. Set to Myy for forms containing data from multiple segments where nn is the underlying sequential query number, e.g. M01, M02, M03. |
For example, form name frm099LNPS01M01 identifies a Stage 1 form, which refers to fields in multiple segments of Business Object 099 for Product Sales in London.
For the Controller backend database, control names on forms and reports were of variable length, freeform and were occasionally as set by the Create Form Wizard.
For the User front-end database, the control names on forms and reports was of variable length, freeform and functionally descriptive. Further, the control-type indicator as described in the following table, precede all control names in this database.
Table 10 ¢ Control naming convention
| Control type | Control-Type indicator |
| Text box | txt |
| Combo box | cbo |
| List box | lst |
| Option group | grp |
| Labels | lbl |
| Command buttons | cmd |
| Option button | opt |
Field names for Tables were as described in the Business Object Import Record Definition (BOIRD) Table within the Controller backend database. Further, all field names were proceeded by the literal fld to identify the object.
| Modal | Yes | |
| Header height | 1.5 cm | |
| Form Width | 20 cm | |
| Detail Height | 10.78 | |
| Label-only Controls | Labelxxx | |
| Text box labels | lblxxxfieldname | xxx is Man or Elc or Key
fieldname excludes ōfldö |
| Text Box controls | txtxxxfieldname | xxx is Man or Elc or Key
fieldname excludes ōfldö |
| Form on-open | to maximise form | |
| Scroll bars | neither | |
| record selectors | yes | |
| navigation buttons | yes | |
| dividing lines | no | |
| auto resize | yes | |
| auto centre | yes | |
| pop-up | yes | |
| modal | yes | |
| boarder style | dialog | |
| control box | no | ōYesö will show the close button |
| min/max buttons | none | |
| close button | yes | |
| whatÆs this button | no |
The above batch migration database was designed and created from scratch after examining the Food and Drugs Administration requirements for an audit trail, and user requirements for data verification and editing during the migration process. Significant error reduction was achieved through automation of database table creation. Data security and integrity were also considered and built into the design. Another sample work page will show part of the code and test routines for the above database.
Please click on the link below to return to the English Home Page
If you require some further information, Please Contact Me
Copyright ® 1999 Dr. M. A. Meshkot
This page was last updated February 2006